TypeWell transcribers are trained in meaning-for-meaning transcribing. Why? Because it completely conveys the speaker’s intended meaning in fewer words so the reader can quickly assimilate the content and participate in the discussion as it happens.
A meaning-for-meaning transcript reflects the speaker’s emphasis, pauses, and body language — each of which can significantly impact the reader’s comprehension.
For example, a speaker might modify the meaning of a sentence with a gesture or a facial expression, or by emphasizing one word over others. A meaning-for-meaning transcript includes that non-verbal, nuanced information.
In contrast, a verbatim transcript can be cumbersome to read, especially in real time.
A brief explanation of the difference between meaning-for-meaning and verbatim transcribing, followed by a lecture excerpt transcribed using the TypeWell meaning-for-meaning approach. This video was produced by Intellitext LLC in collaboration with TypeWell.
TypeWell Services
Verbatim (word-for-word systems such as CART or voice writing)
35-60 hours of dedicated training time over the course of 2-3 months to achieve novice level
2-3 years of consistent experience to achieve intermediate skill level
3-5 years for CART writers
1-2 years for voice writers
$899 Basic Skills Training Package
Includes 2 first-semester Skill Consultations conducted by a TypeWell teacher for quality assurance
$1,000+
$440/year
Includes free software updates and tech support
Includes free streaming text platform (Web Linking)
$4,000+
May require periodic upgrades/additions
Add-on streaming text costs (per minute), depending on platform
Wording and grammar is typically condensed for clarity, but may occasionally be expanded for disambiguation or to convey a speaker’s nonverbal cues
“Accuracy” is measured in terms of capturing the speakers’ intended meaning
Emphasis on clear formatting and paragraphing for ease of readability and to minimize eye fatigue
Minimizes reading time so the reader can look away from the screen at times to participate in real-time conversation
Emphasis on capturing every spoken word, not necessarily focused on clarity, grammar, or accuracy
“Accuracy” is measured in terms of word count rather than conceptual accuracy
Minimal to no paragraphing, which can result in dense blocks of text that lead to eye fatigue
Depending on software or settings, some transcripts are typed IN ALL CAPS
Individuals who want access to the meaning of what’s spoken
Individuals who need a concise, clear transcript to study or review afterward
Individuals who want every word or utterance captured in text format
Individuals who need a verbatim transcript for study or reference afterward
We believe in fairness! If you see missing or inaccurate information about our competitors, please contact us so we can update it.
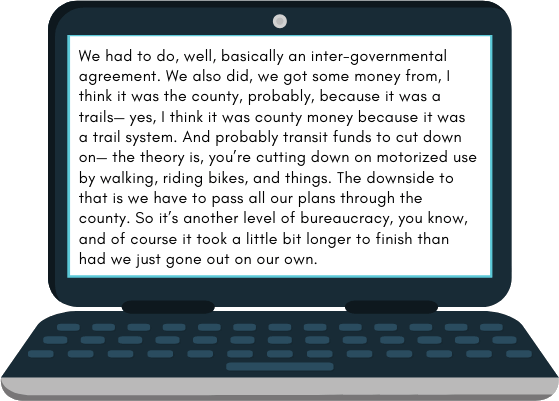
Meaning-for-meaning
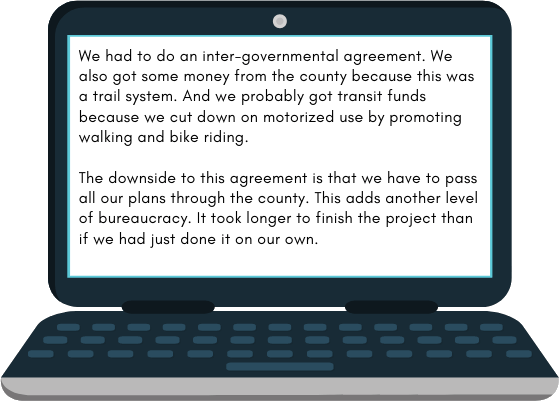
Verbatim